Just recently it came to my attention that Readwise now offers an App called Reader. Readwise has been around for several years and is a tool to manage your personal highlights discovered in text somewhere in the digital sphere. Recently, they added Reader as a fully fledged
- Feed reader
- Read-it-later client
beautifully combined in a single app, which really reduces the friction I experienced with Readwise before.
The fancy part is that Reader integrates the highlighting mechanism of Readwise. Plus, it offers automations for several note taking applications, such as Obsidian an Notion. Supernotes, however, is not officially supported.
End of Story?
Not at all, for where there is an API, there is a way! We can use pipedream to connect both tools using their APIs.
I created a workflow on pipedream (which is really lowcode) that creates a new note whenever I add a highlight to Readwise. This is as easy as selecting text in the Reader app, or in the Browser using the Readwise extension.

Pipedream now creates a note, which respects the syntax I traditionally use for literature notes. I can even add a personal note to the selection in Readwise, which is then also exported.
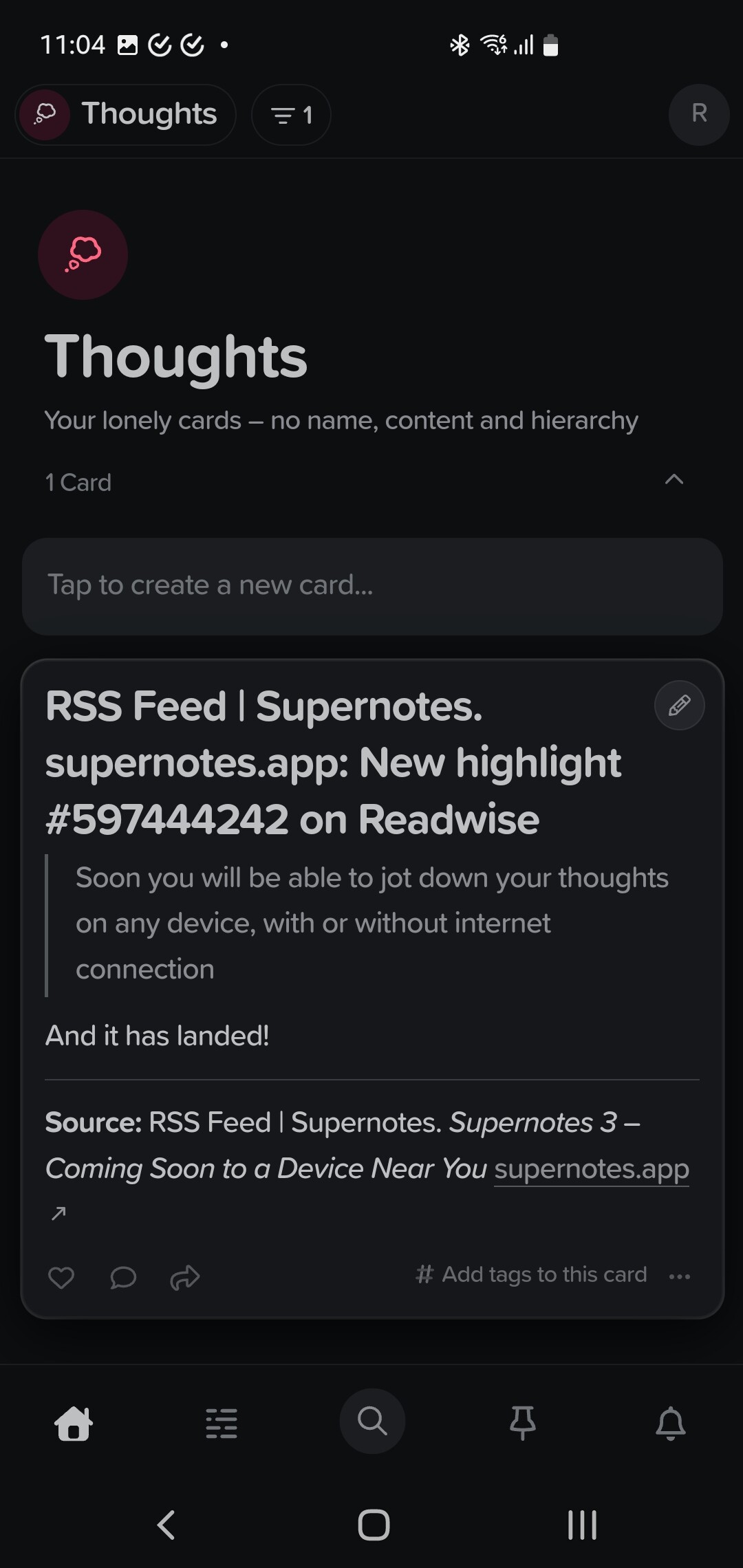
Pretty sweet, right? This even works for Youtube videos, as Readwise Reader allows for highlighting text in the transscript!
In pipedream, I had to insert a Python step to get details on the book from the Readwise API, particularly the website title and author that I use to compose the note. Feel free to ask if you have any questions on the details.
Disclaimer: I am not affiliated with either Readwise, Pipedream or Supernotes.